
Jan Overgoor在Airbnb的博客Nerds上分享了这篇文章。通过案例讲述了在利用A/B测试推动产品决策时应该注意的部分问题,如:A/B测试应该做多久、在情景中去解释A/B测试的结果、为什么应该做A/A测试等。
为什么要做A/B测试?
测试能够让我们简单而直接的进行因果推断。如图1,我们一般很难只是通过简单的观察来了解是否行为导致了结果或者行为的影响力有多大。
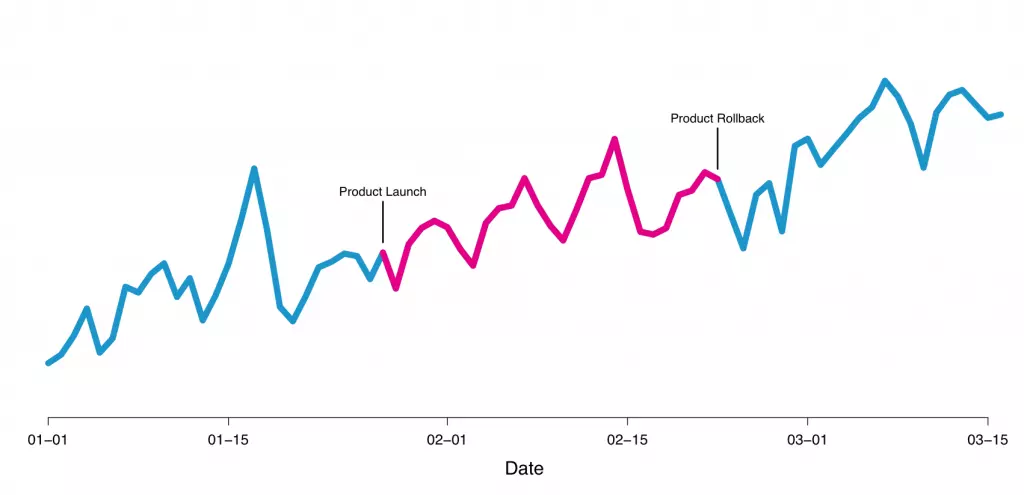
通常外界的影响因素比产品本身变化对测量指标的影响要大许多。用户在工作日/周末、不同季节、不同天气情况下、因为网页广告或主动探索触达的产品都可能会表现出截然不同的行为模式。实验测试的方法能够帮助我们控制这些额外的因素。如在下图2中展示了一个Airbnb采用实验测试并最终拒绝的功能。Airbnb曾希望通过这个功能让用户在搜索结果中筛选产品的价位信息,但测试结果发现用户使用这种筛选方式的频率反而不如原有的筛选器。

在Airbnb如何进行的A/B测试
目前市场上有着许多的公司提供进行优秀的A/B测试工具,也有部分公司将内部的测试系统开源提供给他人使用如,Cloudera的Gertrude, Etsy的Feature,以及Facebook的PlanOut等。
Airbnb所提供的服务有着一定的特异性:首先,用户不需要注册/登录以获取服务,因此很难讲用户和行为捆绑在一起;其次,用户在预定房间的过程中更换实验的设备(PC和手机);另外,预定的过程可能会长达数天,因此需要等待时间以确定用户完成/放弃预定流程;最后,预定的成功还取决于空房的数量以及其主人的响应与否,而这些因素是Airbnb所不能掌控的。综合考虑这些因素后,Airbnb自建了用于实验的A/B测试系统。
A/B测试中通常以点击率或转化率作为评价的指标。在Airbnb,预定的流程同样很复杂:首先,旅客需要搜索获得房间的信息,然后再联系相关的房主;接下来,房主房主将决定是否接受旅客的需求;然后,旅客才能真正预约到房间。除此之外,还有其他的路径能够进行预约---旅客可以不需要联系房主就能预约某些房间,或者提交预约需求后直接到达最后一步。预约流程中的四个步骤如图3所示。尽管在测试过程中需要考虑4个阶段间的转化,但Airbnb将从搜索到最后预定的整体转化率作为测试的主要指标。

A/B测试需要持续多久?
对于在线的A/B测试而言,普遍的疑惑在于需要进行多长的时间来收集数据结果并由此得出结论。对于使用P值作为‘终止符’的实验而言,应该在实验进行之前就已经预估好了样本量和效应量,因此可以及时停止实验。但如果你只是持续监测实验的进程和P值的变化,那么即使在不存在显著效应的时候,你有也机会观察到显著的影响。另外一个常见的错误则是因为没有及时观察到显著效应而过早地结束测试。
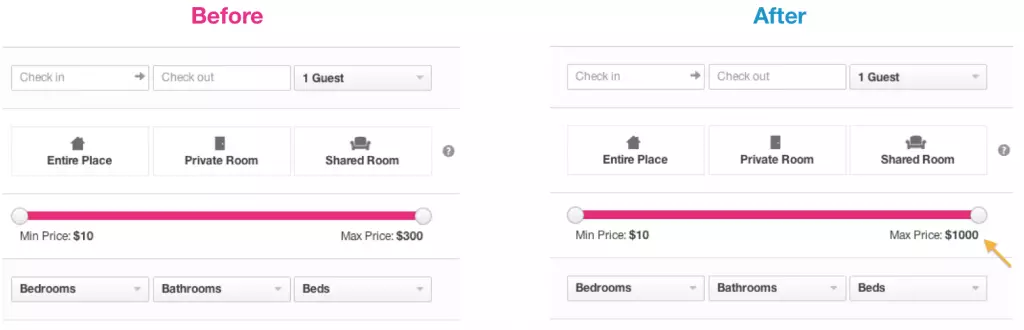
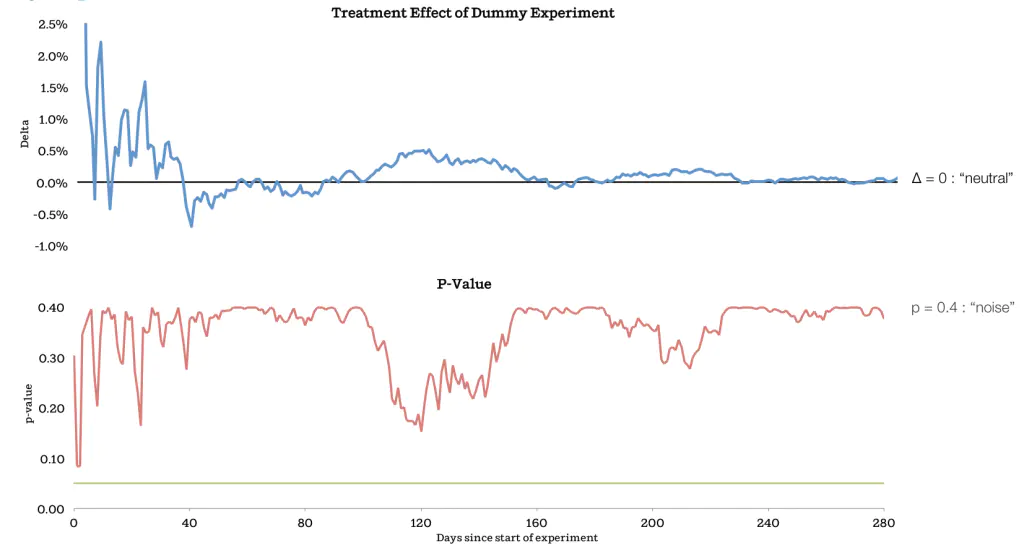
下图4中展示的是Airbnb所进行的一次实验。新版中将搜索界面中价格筛选工具的范围从300改到1000美元。
在图5中展示了A/B测试随着时间推进的结果。上部分的线条展示的为改版效果(新版/旧版-1),而底部的线条为随时间变化的p值。可以看到的是,p值的曲线在7天后达到所谓的0.05的统计学显著,此时的改版的效应值为4%。如果A/B测试到这里结束,则可能的出的结论是新版比旧版对预约的达成有着显著的促进作用。但Airbnb维持了测试继续进行,而最终可以看出测试得出的结果是新旧版筛选器对预约的达成全无影响,效应值的变化基本可以归为是统计噪音。
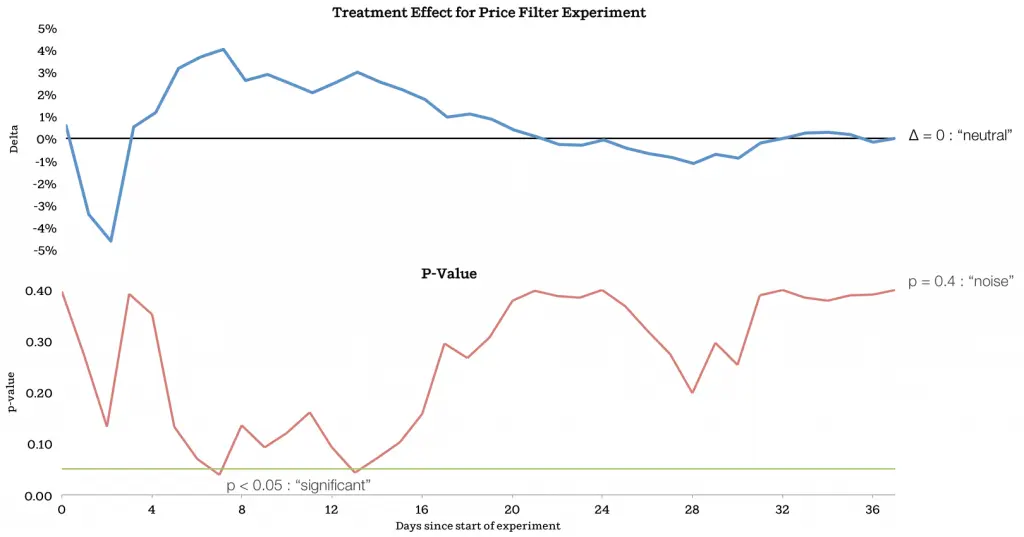
为什么Airbnb没有在数据达到0.05显著时停止A/B测试?因为就Airbnb而言,这样在早期观察到的显著差异随时间变化成为无差异的现象并不罕见。可能的原因有很多:1.预约的流程普遍会比较长,所以测试早期快速完成的预约会对整个测试结果有着较大的影响;2.传统的显著值可能并不适用于现在动辄成千上万的用户测试;3.监控测试的进程意味着每多一次测算p值,也多一点儿收获一个低于0.05的p值的可能。
讲一些题外话,熟悉Airbnb网站的用户可能会注意到它现在采用的正是新版的筛选器。尽管A/B测试的结果表明新版筛选器并不会提升预约的数量,但确实有部分用户会希望有这样的筛选器能够更快找到高端房源,因此Airbnb决定在不损害已有数据的情况下,为这些用户做出改变。
回到正题:一次A/B测试应该运行多久?为了防止二类(存伪)错误,最好的做法是能够在测试开始前便确定好新版需要达到的最低效果,并根据样本量(每日新增用户)和期望的显著值计算好测试需要进行的时间。Evan Miller就提供了这样一个在线计算工具:点击打开。
还有一个问题在于,通常很难确定新版应该要有多大的效果或者会有怎样的效果:有可能它会带来巨大的成功,然而由于测试时间过长而耽误了发布以至于损失过多的利益;或者也有可能A/B测试会导致产品BUG,则越早停止测试越好。
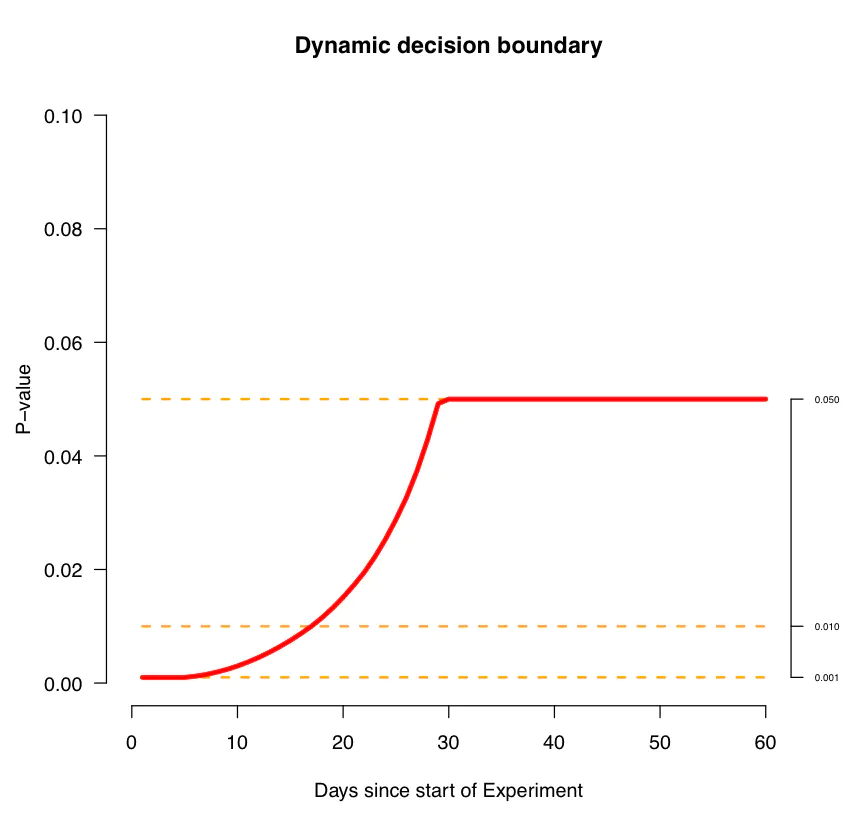
有时候也会碰到测试结果在预定时间之前便触及显著水平的情况。所以在P值之外建立一个新的测试指标就显得很有必要了。如同前文中所述的案例,可以看到在测试首次达到显著水平的时候,效应量(新/旧-1)的图线走势看起来并没有完全饱和。有时候这样的直觉思维有利于判断某个显著结果是否已经稳定下来吗,而这样的直觉通常需要以怀疑主义对待早期的显著结果。这就意味着,在最测试的早期采用较低的p值来判断测试结果的显著性,而随着更多的数据进入,二类错误的可能性开始降低,则可以随之提高接受结果的p值。
Airbnb通过模拟测试获得动态的P值曲线来判断一个早期的显著值是否值得信任。通过在模拟Airbnb的经济生态中引入各种变量以获得不同情况下的效果量和置信度,并以此为依据判断新的产品设计是否存在真的影响。下图6中展示了某次模拟测试所得到的决策边界(注意这个示例是在某些特定变量所得到的曲线,并不能直接适用到其它的情况)。
对测试结果进行情景化的解释
A/B测试中需要避免的另一个问题是习惯性的将测试结果当做一个整体来看待。一般而言,从某个固定的测量维度来评估测试的结果是没错的,这样做通常可以避免在多个维度中挑选最符合“需要”的数据,而故意忽视不符合假设的结果。但同样的,只是单纯的考虑一个维度也意味着脱离了情景来看待数据,而有时候这些不同的情景可能完全改变你对测试结果的解释。
举个例子来说,2013年Airbnb对搜索页进行了改版设计。对于Airbnb而言,搜索页算是业务流程中最基础和重要的页面了。因此,能否准确的确定改版的效果是非常关键的。在下图7中可以看到搜索页改版前后的变化:新版中更加强调了房源的图片(Airbnb为房主提供专业的摄影师以获得这些图片)和标记了房源所在位置的地图。
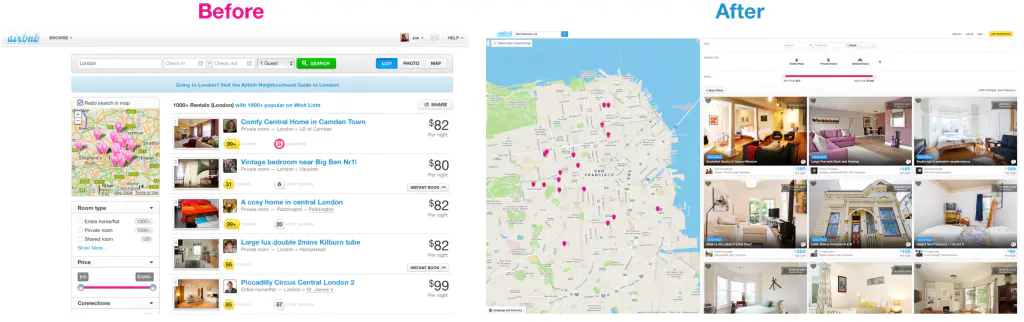
Airbnb为改版项目投入了许多的资源,设计人员预测新版肯定会表现得更好,定性的研究也表明确实如此。尽管不直接向全部用户发布新版可能意味着大量的利益损失,但Airbnb还是延续着其‘测试文化’推进了针对搜索页的A/B测试以评估其真正的效果。
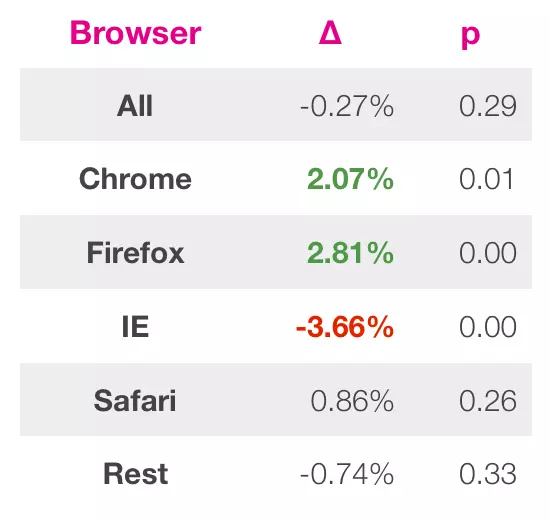
在等待了足够长的时间过后,A/B测试的结果反馈出新版并没有带来更多的预约达成。这当然是难以接受的,所以Airbnb的数据分析员决定从情景出发,将数据细分到不同的情景中来判断究竟为什么改版没有带来足够的效果。事实证明,问题都处在Internet Explorer上了:如图8中所示,除了来自IE的访问以外,新版在其它主流浏览器上的表现都是优于旧版的。在修复相关的问题后,源自IE的数据也有了超出2%的增长。
除了告诉我们在做QA的时候要尤其注意IE以外,这个案例也强调了从多个维度对测试结果进行解释的价值。你可以根据浏览器、国家、用户类型等多个维度分解数据来源进行分析。但需要注意的是,不要为了找到‘显著’的结果而刻意去分解数据。
为什么要做A/A测试?
最后,在A/B测试中人们常犯的一个错误在于自以为测试在理想的状态中进行。不论是使用自建的还是第三方测试系统,都应该尽量避免这种想法:测试系统很可能反应的并不是完全的真实。导致这些差异的原因可能是测试系统本身的问题或是你没有正确地使用它。避免这种错误的方法就是:当你看到某个特别理想的结果的时候,假设它是有问题的,然后通过排除其他可能的原因来证明它是准确的。
A/A测试就是用于这些检测的简便方法:A组和B组使用相同的产品版本,如果二者的结果表现出显著差异则意味着A/B测试的结果差异是由于A/B组自身而不是产品的差异所导致的。如图9所示,如果测试系统是正常/使用正确的,那么A/A测试通常会反馈出无差异的结果(当然如果将数据分解到不同的维度来检测,则你总会在某个维度上看到一些显著的结果)。
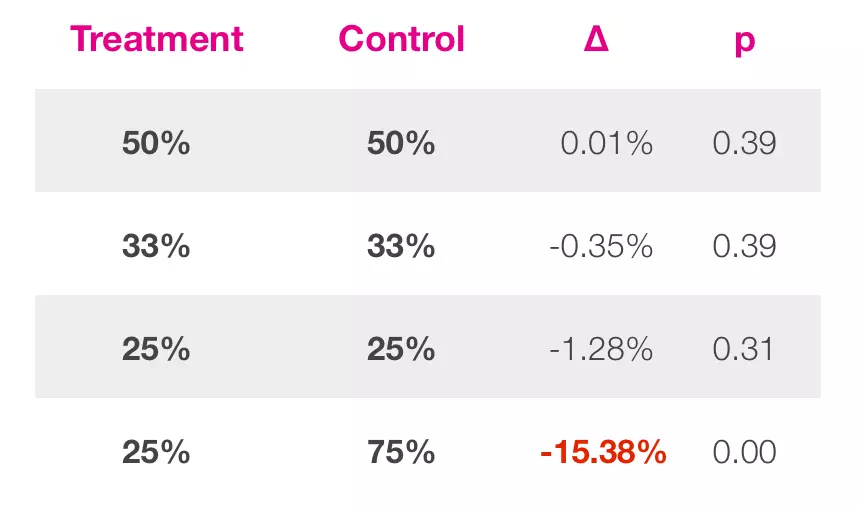
Airbnb通过不断的A/A测试来针对自建测试系统的潜在问题。在某次测试中,Airbnb检测了A/B组间样本量差异的影响。图10中列出了在全部用户间取不同比例作为A/A测试的两组间所得到的实验结果。可以看到当两组的样本量相同的时候,测试的结果反馈出无显著差异;而当两组的样本量存在明显先差异(25/75)的时候,测试反馈了显著的结果。Airbnb检测了这一结果的原因,发现这与其测试系统对未登录用户的分组有关。尽管这一错误是Airbnb自建的测试系统所特有的,但这个案例也表明了A/A测试的重要性和价值。
总结
严格控制的实验是产品研发过程中强有力的决策工具。希望这篇文章能够帮助大家更有效地进行A/B测试。
首先,确定测试运行时间的最好方式是提前计算好预期的显著值所需要的样本量。如果测试在早期就反馈了理想的结果,最好是带着怀疑的态度等待测试运行结束。灵活的利用p值将有利于进行产品决策:在早期采用较低的p值(如0.01),然后随着测试的进行而逐渐提高p值(如0.05)。
第二,从不同的情景中去理解测试的结果是非常重要的。你应该尝试将数据分解到不同的维度,然后再去理解不同维度下产品的效果。但是需要注意的是,A/B测试的目的在于为了优化产品决策,而不是为了最优化测试结果。优化测试结果通常导致为了获得一定短期利益的机会主义决策。
最后,验证你所使用的测试系统是否如你所期望的一样工作。如果A/B测试反馈的结果有问题或者是过于理想,你都应该仔细核验它。最简单的方式就是进行一次A/A测试,重复进行A/A测试有利于了解测试系统的工作原理,并帮助对数据结果进行更全面的解释。
PS. Jan Overgoor在原文中更多的使用的是‘Experiment(即,实验)’这个名词。在翻译过程中统一以‘A/B测试’来表述。
作者:IvanMu